
粒度
数据建模
粒度
粒度
我相信大多数人都知道这个术语,但不确定你在其重要性方面有多准确。
数据的粒度意味着数据的层次分解。
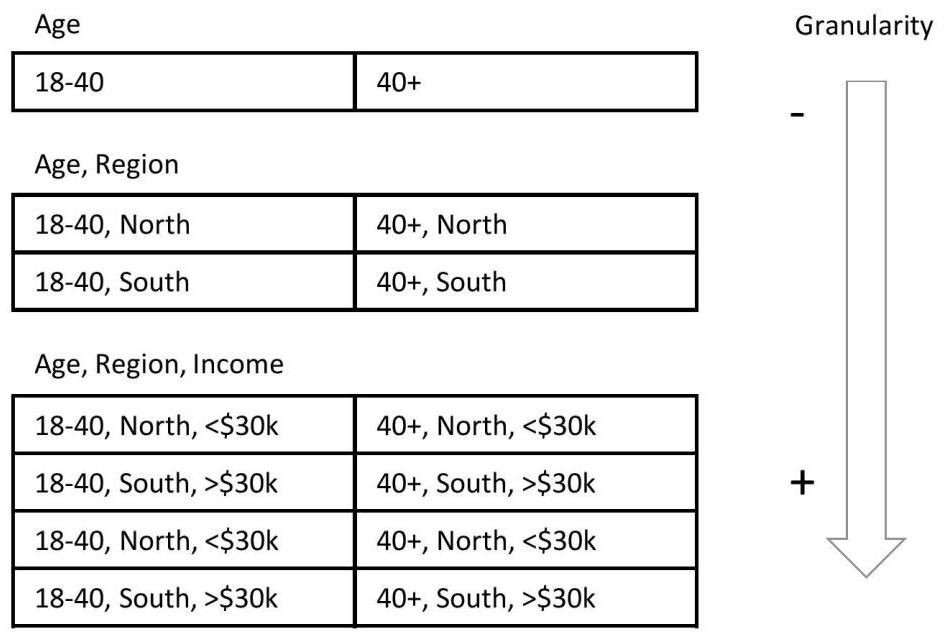
一般来说,人们认为了解实体的所有相关细节就是粒度,但问题是细节的级别是多少?
例如,详细信息可以是姓名,电子邮件和联系电话,出生日期,颜色,血型,家庭住址,公司,角色,薪水,父亲姓名,母亲姓名等。这是较低的粒度级别吗?不,当我们说最低级别的粒度时,我们可以分解。
Ø将名字分成名、中间名和姓
Ø将地址分为公寓号码、建筑名称、街道、区域、城市、区、地区、国家、邮政编码等。
在 OLTP 系统中,粒度必须尽可能低,在 OLAP 系统中,粒度可能取决于业务用例。
现在,当我们已经确定了粒度是什么,让我们讨论何时需要它。数据整理、数据挖掘、数据科学等都使用原始数据进行分析和分析(Analysis and Analytics)。而且当我们说原始数据时,粒度越低,DSS的模型结果就越好。
主数据管理、元数据管理、数据血统、数据质量、数据完整性、数据清洗/清理/洗涤、商业智能仪表盘、数据建模、数据分类和数据聚类等,都是基于数据模型的粒度级别产生结果的。
创建数据模型的第一步应该是了解系统或业务用例期望的粒度级别,例如日期与日期时间数据类型可以改变粒度级别。粒度级别越低,行数就越多,可以规划更多的钻取和切片/切块。
不要错过浏览主题,即基数。

中心")



扫码联系
电话联系